Network
-
-
- 此人的linux网络系列文章很不错

Articles
网络包收发流程及缓冲区问题
接收流程
- 当一个网络帧到达网卡(NIC, Network Interface Card)后,网卡会通过 DMA 方式,把这个网络包放到收包队列中;然后通过硬中断,告诉中断处理程序已经收到了网络包。
- 接着,网卡中断处理程序会为网络帧分配内核数据结构(sk_buff),并将其拷贝到 sk_buff 缓冲区中;然后再通过软中断,通知内核收到了新的网络帧。
- 接下来,内核协议栈从缓冲区中取出网络帧,并通过网络协议栈,从下到上逐层处理这个网络帧:
- 在链路层检查报文的合法性,找出上层协议的类型(比如 IPv4 还是 IPv6),再去掉帧头、帧尾,然后交给网络层。
- 网络层取出 IP 头,判断网络包下一步的走向,比如是交给上层处理还是转发。当网络层确认这个包是要发送到本机后,就会取出上层协议的类型(比如 TCP 还是 UDP),去掉 IP 头,再交给传输层处理。
- 传输层取出 TCP 头或者 UDP 头后,根据 < 源 IP、源端口、目的 IP、目的端口 > 四元组作为标识,找出对应的 Socket,并把数据拷贝到 Socket 的接收缓存中。
- 最后,应用程序就可以使用 Socket 接口,读取到新接收到的数据了。
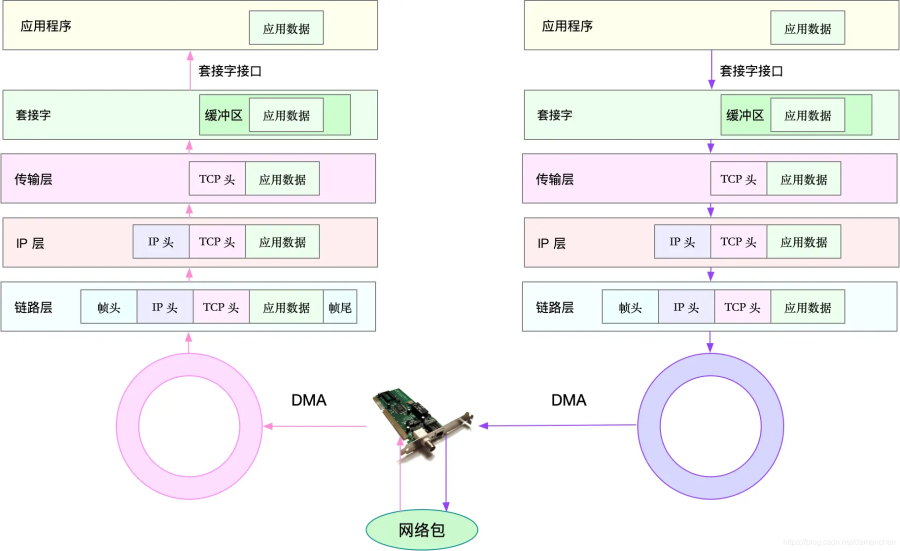

缓冲
- 网络包的接收和发送流程涉及到了多个队列和缓冲区,包括:
- 网卡收发网络包时,通过 DMA 方式交互的环形缓冲区;
- 网卡中断处理程序为网络帧分配的,内核数据结构 sk_buff 缓冲区;
- 应用程序通过套接字接口,与网络协议栈交互时的套接字缓冲区。
- 这些缓冲区都处于内核管理的内存中,实际上,sk_buff、套接字缓冲、连接跟踪等,都通过 slab 分配器来管理。可以直接通过
/proc/slabinfo来查看它们占用的内存大小。 - 查看 socket 缓冲区大小:
cat /proc/sys/net/ipv4/tcp_rmem(for read)cat /proc/sys/net/ipv4/tcp_wmem(for write)
ifconfig或者直接查看/proc/sys/net/ipv4/下的对应数值,可以查看 drops, overrun, errors 等数值,如果皆为0,则不用考虑更改缓冲。
以太网详解
- MAC: Media Access Control 即媒体访问控制层协议。MAC由硬件控制器及MAC通信协议构成。该协议位于OSI七层协议中数据链路层的下半部分。一般以太网MAC芯片的一端连接PCI总线,另一端连接PHY芯片上通过MII接口连接。
- PHY: Physical Layer 是IEEE802.3中定义的一个标准模块,STA(Station Management Entity,管理实体,一般为MAC或CPU)通过MIIM(MII Manage Interface)对PHY的行为、状态进行管理和控制,而具体管理和控制动作是通过读写PHY内部的寄存器实现的。
- MII:Media Independent interface 即介质无关接口,它是IEEE-802.3定义的行业标准,是MAC与PHY之间的接口。
- RMII:Reduced Media Independant Interface, 精简MII接口,节省了一半的数据线。
- SMII:Serial Media Independant Interface, 串行MII接口。
- GMII:Gigabit Media Independant Interface,千兆MII接口。GMII采用8位接口数据,工作时钟125MHz,因此传输速率可达1000Mbps。GMII接口数据结构符合IEEE 802.3-2000 标准。
- RGMII:Reduced Gigabit Media Independant Interface, 精简GMII接口
低延时网络架构
- 一个网络请求从用户发出,到最终处理完毕,其延时总体上可以划分为两块,一是网络转发延迟,二是系统处理延迟。
- 高频量化交易公司在网络转发延迟上采取的优化手段:
- 微波传输。光信号直接在空气中传播,略慢于真空,而光纤中的光速度大致为真空光速的 50% - 66% 左右,光纤铺设经常需要拐弯。
- InfiniBand 替换以太网
- 低延迟交换机(Arista)
- 就近部署(Co-location)、拉网络专线等。
- 在系统处理延迟上:
- 大量地采用 Kernel By Pass 来降低内核处理延迟,部分公司还采用了 RDMA 类的技术。
- 在计算上将大量的计算密集型的工作从 CPU 上卸载到 FPGA 中完成。
- 传统的优化手段量化公司也在用,例如大内存换时间,高频 CPU、绑核等等。